 Popular resources
Popular resources






![]() What's it?
What's it?
The Chromosome-centric Human Proteome Project (C-HPP) aims to map and annotate the entire human proteome by the "chromosome-by-chromosome" strategy. As the C-HPP proceeds, the increasing volume of proteomic data sets presents a challenge for customized and reproducible bioinformatics data analyses for mining biological knowledge. To address this challenge, we updated the previous static proteome browser CAPER into a higher version, CAPER 2.0 - an interactive, configurable and extensible workflow-based platform for C-HPP data analyses. In addition to the previous visualization functions of track-view and heatmap-view, CAPER 2.0 presents a powerful toolbox for C-HPP data analyses and also integrates a configurable workflow system that supports the view, construction, edit, run, and share of workflows. These features allow users to easily conduct their own C-HPP proteomic data analyses and visualization by CAPER 2.0. We illustrate the usage of CAPER 2.0 with four specific workflows for finding missing proteins, mapping peptides to chromosomes for genome annotation, integrating peptides with transcription factor binding sites from ENCODE data sets, and functionally annotating proteins.
![]() How to use it?
How to use it?
The updated CAPER is available at http://www.bprc.ac.cn/CAPE. Tutorial: http://111.198.139.90/caper2/static/documentation/index.html
![]() Institute
Institute
Beijing Proteome Research Center(BPRC) (北京蛋白质组研究中心)
![]() Author
Author
Dan Wang(王聃) ,Zhongyang Liu(刘中扬)
![]() Support
Support
![]() Publication
Publication
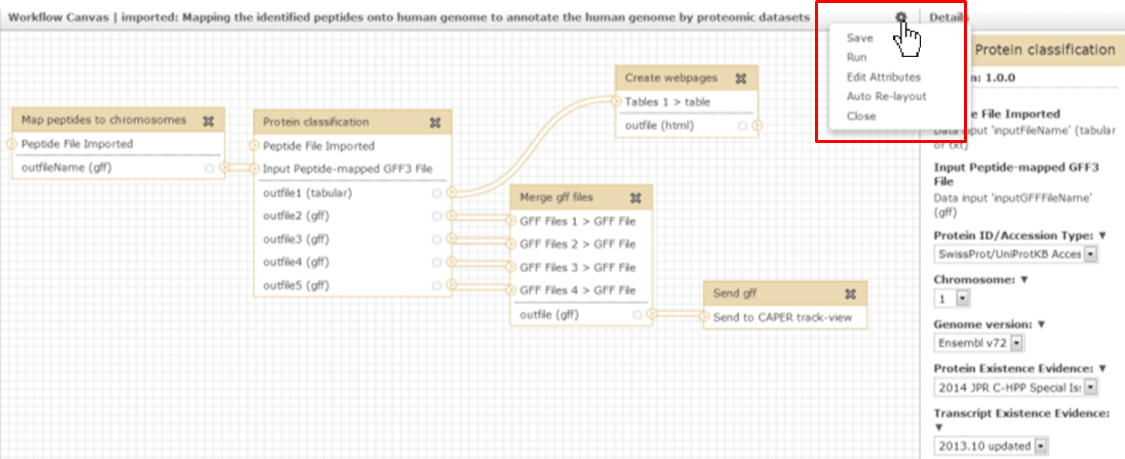
![]() Figure
Figure
![]() Funding source
Funding source
[{"id":"3","name":"CNHPP int'l project 3:2014DFB30020(中国人类蛋白质组学数据的知识发现)"}]