 Popular resources
Popular resources






![]() What's it?
What's it?
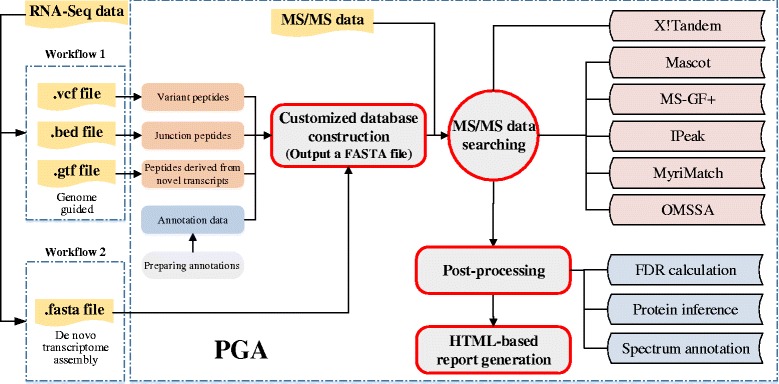
A pipeline with an R package, assigned as a PGA utility, was developed that enables automated treatment to the tandem mass spectrometry (MS/MS) data acquired from different MS platforms and construction of customized protein databases based on RNA-Seq data with or without a reference genome guide. PGA can identify novel peptides (SNV, INDEL, novel splice junction and transcript-derived peptides ) and generate an HTML-based report with a visualized interface.
![]() How to use it?
How to use it?
The pipeline of PGA, aimed at being platform-independent and easy-to-use, was successfully developed and shown to be capable of identifying novel peptides by searching the customized protein database derived from RNA-Seq data.The software is freely available from http://bioconductor.org/packages/PGA/, and the example reports are available at http://wenbostar.github.io/PGA/.
![]() Institute
Institute
Shenzhen Huada Gene Research Institute (深圳华大基因研究院)
![]() Author
Author
Shaohang Xu(许少行),Bo Wen(闻博)
![]() Support
Support
![]() Publication
Publication
![]() Figure
Figure
![]() Funding source
Funding source
[{"id":"1","name":"CNHPP int'l project 3:2014DFB30020(中国人类蛋白质组学数据的知识发现)"}]